Professional certification is a necessity in the IT industry. Tertiary education barely scratches the surface of the required skills in the broad range of career paths available to an IT graduate. Some career paths have many certification options available to them. With security being no exception, the problem is that security certifications are misunderstood and often very expensive.
In this post, I will dispense with my thoughts on certification in the security industry and how they may be useful to a security architect. *Note: I had planned one post for my thoughts on this topic, but it seems I have a lot to say. So I have decided to split the post up into a series of posts(this being the first).
Security architecture is a cross-cutting field requiring skills in a wide range of areas. In particular, technical knowledge of enterprise-wide disciplines is essential. In this article, I shall be focusing specifically on the needs of an application security architect.
What certifiable skills does a security architect need?
It is not enough to have a strong affinity towards security. The security architect needs to provide inputs into the other specialized architectures, from a security perspective. Therefore a security architect needs to have good knowledge of network, data, infrastructure, application and enterprise architecture and how to apply security to them. This doesn’t mean the security architect should be looking at getting certification in these areas, but reading about the topics would certainly help where experience in the area has not materialized yet. Network security certifications in particular are usually vendor driven, and this wont help the architect who needs to ideally be technology agnostic in this area.
Having technology specific certifications has its place depending on the architects role, but having generalized certifications will help the architect adapt to a broader business need. Security specific certifications for the most part are technology agnostic, and cover a broad range of topics. But this is where deciding on which certification to do becomes tricky. An application security architect needs to have strong technical skills, knowledge of architectural frameworks, and knowledge of compliance frameworks. In addition they need to know about risk, but most importantly how to communicate that risk in a language the audience understands.
Traditionally, architects from all fields have strayed a bit too far from where they got their hands dirty coding in the early days of their careers. This tends to result in the typical “ivory tower” kind of architecture, which is undesirable. Personally, I feel an architect that is willing to throw together some code to elucidate an idea or proof of concept is extremely valuable. Their code doesn’t have to be amazing, it just has to get the idea across. The engineers can then work with an actual technical artifact as opposed to written documentation. I would stop short of certifying in this area though, as many architects tend to have some level of development background (usually a computer science degree). Provided that the coding skills are exercised once in a while, a computer science degree would typically suffice. An architects code will rarely (if ever) make it to production, so the architect need not be a coding rockstar (it does help, though).
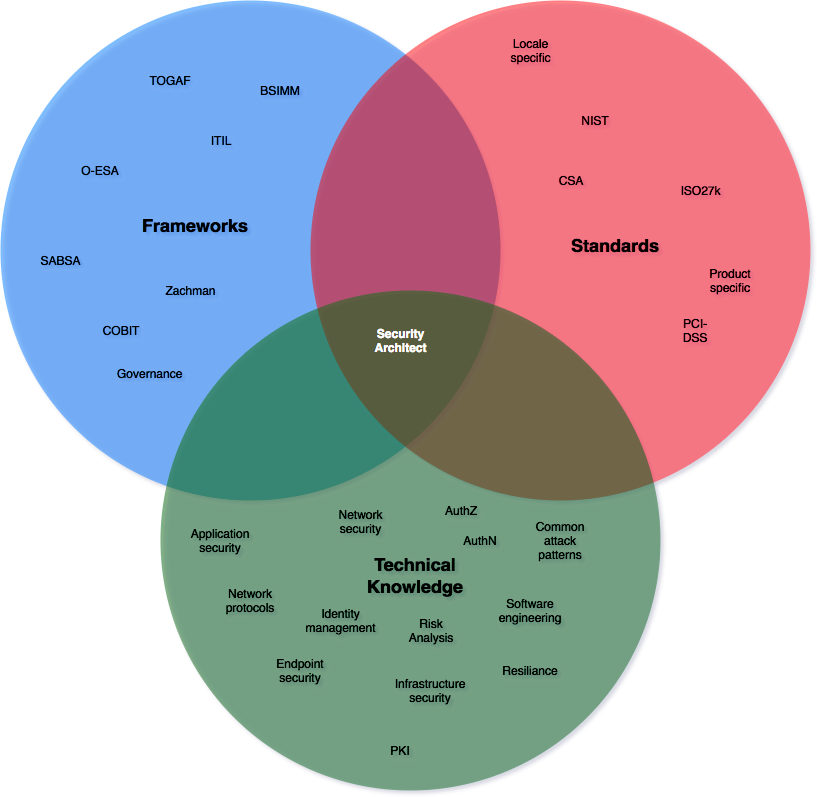
There are of course, many soft skills required of a security architect, but these cant be gained through certification. Similarly to a consultant, an architect will never be an expert in every field. What matters is the ability to use what knowledge they have to understand the environment in which they are working.
This is the first post of a series of posts, which I will be releasing as I complete them. The next posts will be:
Part 2, The state of play: Security certification
Part 3, CISSP: So special it needs its own post
Part 4, What other certifications are out there, and their value